
07.2.2026 Bahar Gidwani
The following is part 2 of a 3-part series on “Big Data.”
We have previously defined “Big Data” and shown how we feel a Big Data system built by CSRHub could help address some problems that exist in collecting corporate social responsibility (CSR) and sustainability data on companies. We have also further described the problems with the currently dominant method of gathering this data—an analyst-based method.
CSRHub uses input from investor-driven sources (known as “ESG” for Environment, Social, and Governance or “SRI” for Socially Responsible Investment), non-governmental organizations, government organizations, and “crowd sources” to construct a 360 degree view of a company’s sustainability performance.
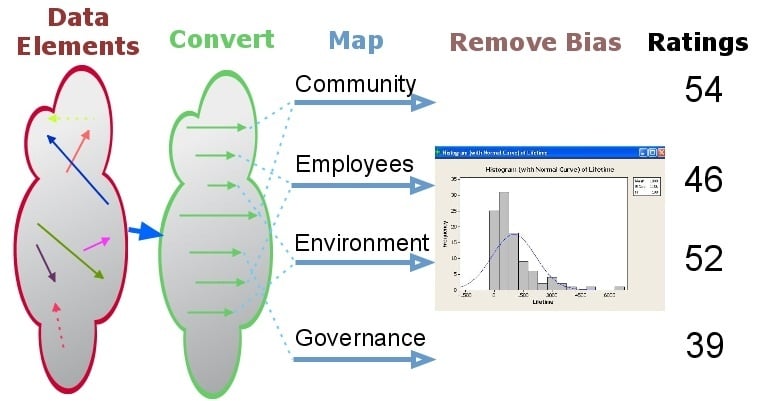
The illustration below shows the steps in our process.
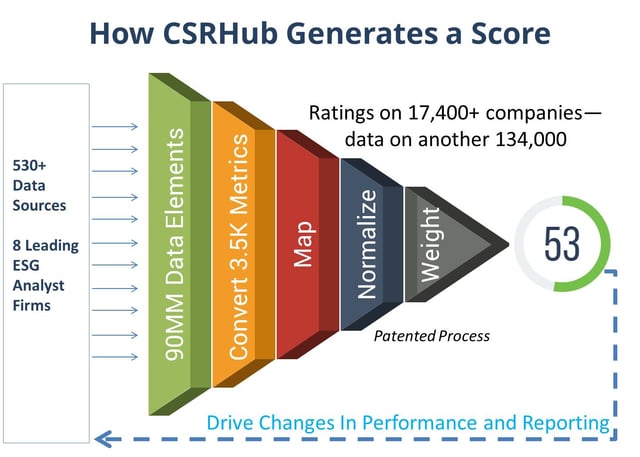
The steps are:
- Convert measurement from each data source into a 0 (low) to 100 (high) scales. This requires understanding how each source evaluates company performance.
- We next connect each rating element with one or more of our twelve subcategory ratings. (Some elements may also map partially or exclusively to special issues such as animal testing, fracking, or nuclear power.)
- We compare each source’s ratings with those for all other sources. Each company we study gives us more opportunities to compare one source’s ratings with another. The total number of comparisons possible is very large and growing, exponentially. We use the results of our comparison to adjust the distribution of scores for each rating source so that they fall into a “beta” distribution that has a central peak in the 50s.
- Some sources match up well with all of our other data. Some sources don’t line up. We add weight to those who match well but continue to “count” those who don’t.
We then repeat steps A to D as many times until we have found a “best fit” for the available data. Each time we add a new source, we go through an initial mapping, normalization, and weighting process.
An Example
It may help explain our data analysis process by using a specific example. (Note that we are using an example from 2014 for a company that has since been split into two parts. This avoids any risk of an implied criticism of an existing company.) Hewlett Packard was a heavily tracked company prior to its split. We had 154 sources of data for this company that together provided 17,571 individual data elements. Only 62 of these data sources provided data for our July 1, 2014 rating—the rest of the data sources provided data for previous periods (our data set goes back to 2008). The 62 current data sources provided 575 different types of rating elements and a total of 610 different ratings values that did not affect/apply to special issues.
After their conversion to our 0 to 100 scale, we mapped the rating elements into our twelve subcategories. We had 1,403 ratings factors. We selected our subcategories to allow an even spread of data across them. You can see that we had a reasonably even spread for Hewlett Packard:
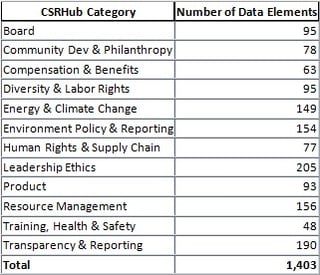
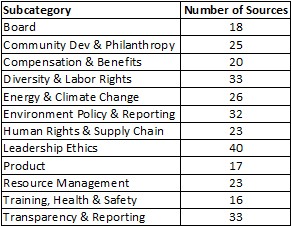
Before we could present a rating, we needed to check first that we had enough sources and enough “weight” from the sources we had, to generate a good score. In general, we require at least two sources that have good strength or three or four weaker ones, before we offer a rating. As you can see, we had plenty of sources to rate a big company such as HP.
Even after normalization, the curve of ratings for any one subcategory may have a lot of irregularities. However, we had enough data to provide a good estimate of the midpoint of the available data, for those ratings we collected and adjusted. Below you can see that some sources had a high opinion of HP’s board while others had a less favorable view. The result was a blended score that averaged to less than the more uniform Leadership Ethics rating.
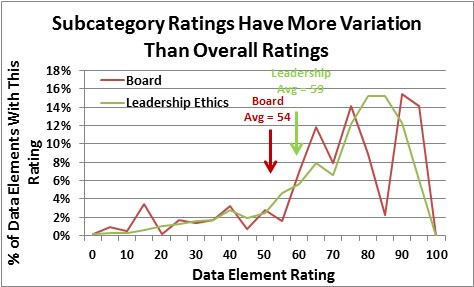
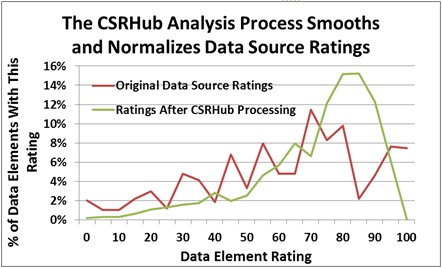
The overall effect of our process is to smooth out the ratings input and make them more consistent. As you can in the illustration below, the final ratings distribution was organized well around a central peak. The average overall rating of 64 was below the peak, which was around 80. The original average rating was 61.
By making a few assumptions about how the errors in data are distributed, one can assess the accuracy of ratings. In a previous post, we showed that CSRHub’s overall rating accurately represents the values that underlie it to within 1.8 points at a 95% confidence interval. Our error bars have continued to decline and now are less than 1 point at this confidence interval.
In our next post, we will discuss the benefits and drawback of using this complex and data intensive approach to measuring company CSR performance.
Did you miss part 1? See part 1 here.
 Bahar Gidwani is CTO and Co-founder of CSRHub. He has built and run large technology-based businesses for many years. Bahar holds a CFA, worked on Wall Street with Kidder, Peabody, and with McKinsey & Co. Bahar has consulted to a number of major companies and currently serves on the board of several software and Web companies. He has an MBA from Harvard Business School and an undergraduate degree in physics and astronomy. He plays bridge, races sailboats, and is based in New York City.
Bahar Gidwani is CTO and Co-founder of CSRHub. He has built and run large technology-based businesses for many years. Bahar holds a CFA, worked on Wall Street with Kidder, Peabody, and with McKinsey & Co. Bahar has consulted to a number of major companies and currently serves on the board of several software and Web companies. He has an MBA from Harvard Business School and an undergraduate degree in physics and astronomy. He plays bridge, races sailboats, and is based in New York City.
CSRHub provides access to the world’s largest corporate social responsibility and sustainability ratings and information. It covers over 17,400 companies from 135 industries in 134 countries. By aggregating and normalizing the information from 530 data sources, CSRHub has created a broad, consistent rating system and a searchable database that links millions of rating elements back to their source. Managers, researchers and activists use CSRHub to benchmark company performance, learn how stakeholders evaluate company CSR practices, and seek ways to improve corporate sustainability performance.

